计算机三级题库网络技术|2017年计算机三级《网络技术》设计与应用试题及答案1
说明:文章内容仅供预览,部分内容可能不全。下载后的文档,内容与下面显示的完全一致。下载之前请确认下面内容是否您想要的,是否完整无缺。
三、设计与应用题(共30分)
1.已知有如下关系模式:Rl(a,b,c),R2(c,d,a),R3(e,f),R4(a,e,g),其中标下划线的属性是主码。请将上述关系模式用适当的ER图表示出来,并用下划线标注出作为实体主码的属性。(10分)
2.设在SQL Server 2008某数据库中有商品表和销售表,两个表的定义如下:
CREATE TABLE商品表(
商品号char(10)PRIMARY KEY,
商品名varchar(40),
类别varchar(20),
进货单价int)
CREATE TABLE销售表(
商品号char(10),
销售时间datetime,
销售数量int,
销售单价int,
PRIMARY KEY(商品号,销售时问))
下面是一个用户定义的多语句表值函数,它接受类别作为输入参数,返回该类别下的每种商品在2012年的销售总利润,并将结果按照销售总利润的降序输出。请补全该函数定义代码。(10分)
CREATE FUNCTION f_Profit(@lb char(10))【1】@ProfitTable【2】(
商品号char(10),
总利润int)
AS
BEGIN
INSERT INTO@ProfitTable
【3】
【4】
END
3.某教务管理系统使用SQL Server 2008数据库管理系统,数据库软硬件配置信息如下:
Ⅰ.数据库运行在两路Intel Xeon E5-2609 2.4GHz CPU(每路CPU4核心),128GB内存、2块300GB15000转SAS硬盘(RAID l)的服务器上;
Ⅱ.服务器操作系统为Windows 2003 32位企业版,安装SP2补丁;
Ⅲ.数据库为SQL Server 2008 Enterprise(32位),数据库中总数据量近130GB。
近一个学期以来,用户反映系统运行缓慢,经程序员定位,确定为数据库服务器响应缓慢,需要进行调优。(10分)
三、设计与应用题
1.【解题思路】
ER模型和关系模式相互转换的一般规则如下:
(1)将每一个实体类型转换成一个关系模式,实体的属性为关系模式的属性。
f21对干一元联系,按各种情处理,如下表格所示。
| 二元关系 | ER图 | 转换成的关系 | 联系的处理 | 主键 | 外键 |
| 1:1 | 1->1 | (2个关系) 模式A 模式B |
(有两种) 处理方式(1): 把模式B的主键, 联系的属性加入模式A 处理方式(2): 把模式A的主键, 联系的属性加入模式B |
(略) | (依据联系的处理方式) 方式(1): 模式B的主键为模式A外键 方式(2): 表A的主键为表B的外键 |
| 1:N | 1->n | (2个关系) 模式A 模式B |
把模式A的主键,联 系的属性加入模式B |
(略) | 模式A的主键为模式B的外键 |
| M:N | m->n | (3个关系) 模式A 模式B 模式A-B |
联系类型转换 成关系模式A-B; 模式A-B的属性: (a)联系的属性 (b)两端实体类型的主键 |
两端实体类型的 主键一起构成模 式A-B主键 |
两端实体类型的主 键分别为模式A-B的外键 |
此题为关系模式转换为实体类型,因此采用实体→关系的逆向思维解题。从模式R1和R2可知,R1和R2为一对一关系,根据这两个模式的拆分可以确定三个实体,此处将这三个实体分别命名为A、B和C。其中A、B和C分别一一对应,且a和c分别是B和C的外键。从模式R1和R4可知,R1和R4为多对一关系,由此确定实体D。从模式R3和R4可知,R3和R4为多对一关系,由此可以确定出实体E。
【参考答案】
a、c为A的候选码,可任选其一做主码。可通过以下ER图来表示: 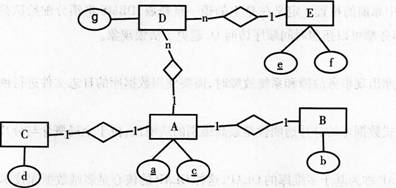
2.【解题思路】
用户定义的多语句表值函数的命令格式为:
CREATE FUNCTION[schema_name.]function name
([{@parameter_name[AS][type_schema_name.]parameter_data_type
[=default]}
[….n]
]
)
RETURNS@return_variable TABLE
[WITH
[AS]
BEGIN
function_body
RETURN
END
[;]
({
J
[
)
题目要求返回指定类别下的每种商品在2012年的销售总利润,并且将结果按照销售总利润的降序输出。采用复合SQL语句的格式,先查出指定类别的所有商品号:SELECT商品号FROM商品表WHERE类别=@lb,其中@lb为函数的传人参数,然后在销售表中用GROUP BY对商品号进行分组,并采用SUM计算每个分组的总和。
【参考答案】
第一空:RETURNS
第一空:table
第三空:SELECT a.商品号,SUM(销售数量*(销售单价一进货单价))AS总利润FROM销售表a JOIN商品表b ON a.商品号=b.商品号WHERE a.商品号IN(SELECT商品号FROM商品表WHERE类别=@lb)GROUP BY a.商品号0RDER BY总利润DESC
第四空:RETURN@ProfitTable
3.【解题思路】
数据库性能优化的基本原则就是通过尽可能少的磁盘访问获得所需要的数据。SQL SERVER性能优化一般从数据库设计、应用程序编码、硬件优化、数据库索引、SQL语句、事务处理几个方面人手考虑问题。
(1)分析阶段:在系统分析阶段往往有太多需要关注的地方,系统各种功能性、可用性、可靠性、安全性需求吸引了我们大部分的注意力,但必须注意的是,性能往往是很重要的非功能性需求,必须根据系统的特点确定其实时性需求、响应时间的需求、硬件的配置等。能有各种需求量化的指标。
(2)设计阶段:例如数据库逻辑设计规范化;合理的冗余;主键的设计;外键的设计;字段的设计;数据库物理存储和环境的设计;数据库的物理存储、操作系统环境及网络环境的设计,皆使得我们的系统在将来能适应较多用户的并发操作和较大的数据处理量。这里需要注意文件组的作用,适用文件组可以有效的把I/O操作分散到不同的物理硬盘,提高并发能力。
(3)系统设计:整个系统的设计,特别是系统结构的设计对性能具有很大的影响。对于一般的OLTP系统,可以选择C/S结构、三层的C/S结构等,不同的系统结构其性能的关键也有所不同。系统设计阶段应归纳某些业务逻辑在数据库编程阶段实现,数据库编程包括数据库存储过程、触发器和函数。用数据库编程实现业务逻辑的好处是减少网络流量并能更充分利用数据库的预编译和缓存功能;索引设计阶段可以根据功能和性能的需求进行初步的索引设计,这里需要根据预计的数据量和查询来设计索引,可能与将来实际使用时有所区别。
(4)编码阶段:编码阶段首先需要所有程序员具备优化意识,也就是在实现功能的同时具备考虑优化性能的思想。数据库是能进行集合运算的工具,所谓集合运算实际是批量运算,即是尽量减少在客户端进行大数据量的循环操作,而用SQL语句或者存储过程代替。这个阶段主要是注意在SQL语句等方面的优化,如:尽量少做重复的工作,用SELECT后跟需要的字段代替SELECT*语句,注意事务和锁,注意I临时表和表变量的用法,慎用游标和触发器,尽量使用索引等。
(5)硬件优化:RAID(独立磁盘冗余阵列)是由多个磁盘驱动器(一个阵列)组成的磁盘系统。通过将磁盘阵列当作一个磁盘来对待,基于硬件的RAID允许用户管理多个磁盘。使用基于硬件的RAID与基于操作系统的RAID相比较可知,基于硬件的RAID能够提供更佳的性能,如果使用基于操作系统的RAID,那么它将占据其他系统需求的CPU周期,通过使用基于硬件的RAID,用户在不关闭系统的情况下能够替换发生故障的驱动器。利用数据库分区技术,可均匀地把数据分布在系统的磁盘中,平衡I/0访问,避免I/0瓶颈等。
(6)事务处理调优:数据库的日常运行过程中,可能面临多个用户同时对数据库的并发操作而带来的数据不一致的问题,如:丢失更新、脏读和不可重复读等。并发控制的主要方法是封锁,锁的含义即是在一段时间内禁止用户做某些操作以避免产生数据不一致。对于事务性能的调优,要考虑到事务使用的锁的个数(在所有其他条件相同的情况下,使用的锁个数越少,性能越好)、锁的类型(读锁对性能更有利)以及事务持有锁的时间长短(持有时间越短,性能越好)等情形。
【参考答案】
根据SQL Server 2008数据库的特性以及题目中的条件,综合给出以下的调优方案。
(1)表结构优化:重新优化数据库设计结构,规范数据库逻辑设计;设计主键和外键;设计合适大小的字段。
(2)硬件优化:购买一块同样大小的硬盘,将硬盘做成RAID5,用以提高数据库读写速度;增加服务器CPU个数;扩大服务器的内存。
(3)索引优化:采用对经常作为条件查询的列设计索引,在查询中经常用到的列上建立非聚簇索引,在频繁进行范围查询、排序、分组的列上建立聚簇索引,对于有频繁进行删除、插入操作的表不要建立过多的索引。
(4)采用视图:合理使用视图和分区视图,在需要更新和删除操作不多、查询操作频繁的表上建立索引视图。
(5)SQL语句优化:选择运算应尽可能先做,并在对同一个表进行多个选择运算时,选择影响较大的语句放在前面,较弱的选择条件写在后面,这样就可以先根据较严格的条件得出数据较少的信息,再在这些信息中根据后面较弱的条件得到满足条件的信息。应避免使用相关子查询,把子查询转换成联结来实现。字段提取按照“需多少,提多少’’的原则,避免“SELECT*”,“SELECT*”需要数据库返回相应表的所有列信息,这对于一个列较多的表无疑是一项费时的操作,采用存储过程,使用存储过程提高数据处理速度。
2017年计算机三级《网络技术》设计与应用试题及答案1.doc
正在阅读:
2017年计算机三级《网络技术》设计与应用试题及答案108-08
2022年江苏省长三角国家技术创新中心(扬州)服务中心招聘公告10-25
银行招聘网:2019浦发银行重庆分行招聘实习生20人10-18
中班班主任转正自我鉴定大全10-12
菜园风景作文500字11-20
2021年山西朔州中级会计职称报名时间及入口(3月10日至3月31日)06-23
我们的节日作文800字11-09
两汉的爱情诗词《留别妻》原文和赏析03-28
Win7系统鼠标右键新建word文档却无法新建word文档的解决方法(图文)05-31
上一篇:初中历史教案:经济重心的南移
下一篇:高一寒假作文:位置最低
相关热搜
推荐文章
热门阅读